인식도 잘되고 하구만
import requests
import json
from gtts import gTTS
import playsound as ps
import speech_recognition as sr
"""
1. 로컬에 ollama와 llama3.1:8b 설치
2. STT를 ko로 고정
3. TTS를 ko로 고정
[의존성 관련]
pip install gtts
pip install ollama
pip install playsound
pip3 install PyObjC
pip install SpeechRecognition
pip install -U pip
pip install -U pyaudio
"""
def speak_text(text):
tts = gTTS(text, lang='ko', slow=False)
tts.save("response.mp3")
# os.system("mpg321 response.mp3")
ps.playsound("response.mp3")
def stt():
r = sr.Recognizer()
with sr.Microphone() as source:
print("Say something! : ")
audio = r.listen(source)
return r.recognize_google(audio, language='ko-KR')
def ollama_chat(text):
url = "http://localhost:11434/api/generate"
data = {
"model": "llama3.1:8b",
"prompt": text
}
header = {'Content-Type': 'application/json'}
response = requests.post(url, json=data, headers=header)
if response.status_code == 200:
print( response.content.decode().strip().split('\n') )
json_obj = response.content.decode().strip().split('\n')
res_data =[json.loads(obj) for obj in json_obj]
res_text = ''
for item in res_data:
res_text += item['response']
# print(res_text)
return (True, res_text)
else:
# print('Error:', response.status_code, response.text)
return (False, response.text)
return (False, '')
if __name__ == "__main__":
# 음성 입력
message = stt()
print('질문: ' , message)
# 생각 답변
(status, text) = ollama_chat(message)
print('답변: ', text)
# 음성 출력
speak_text(text)
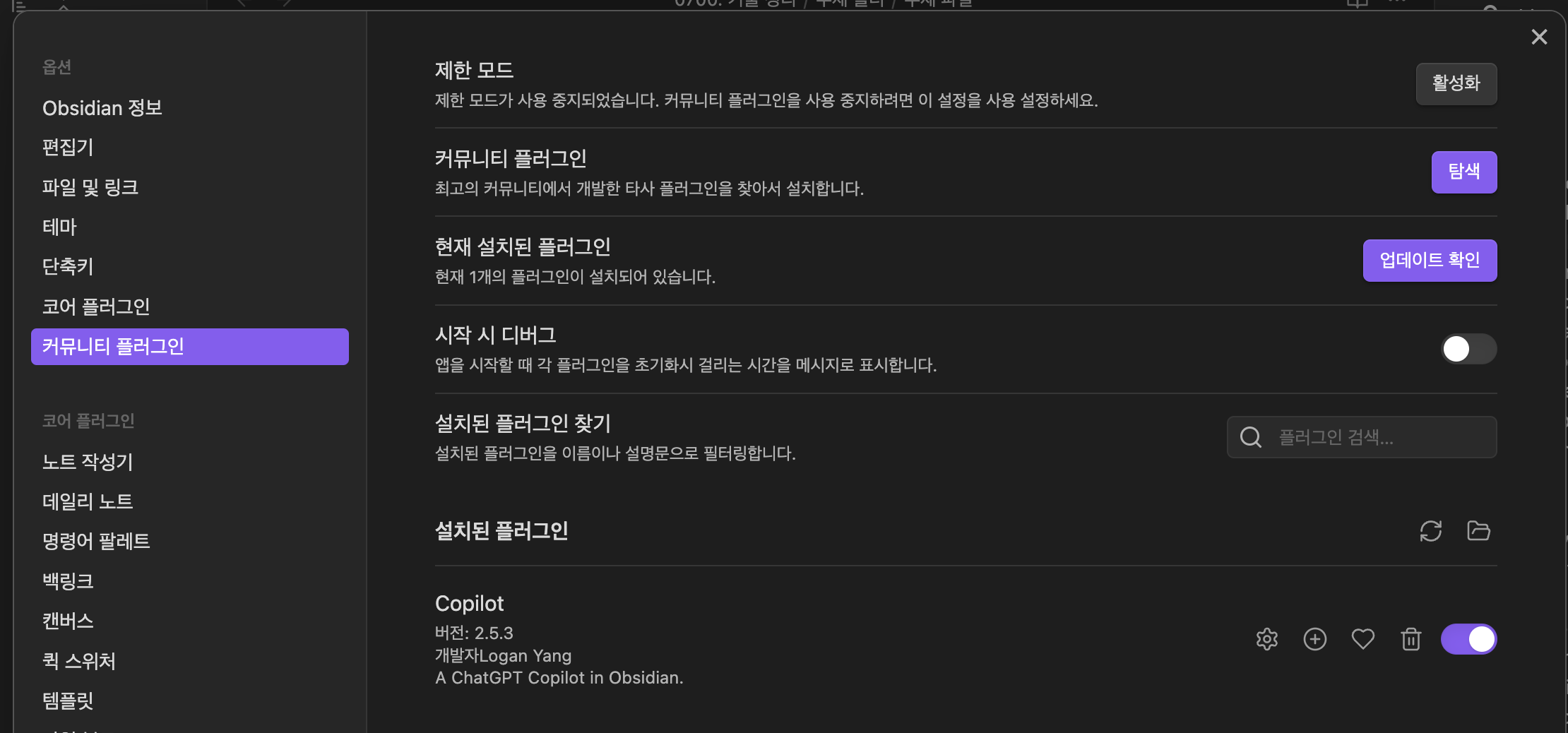
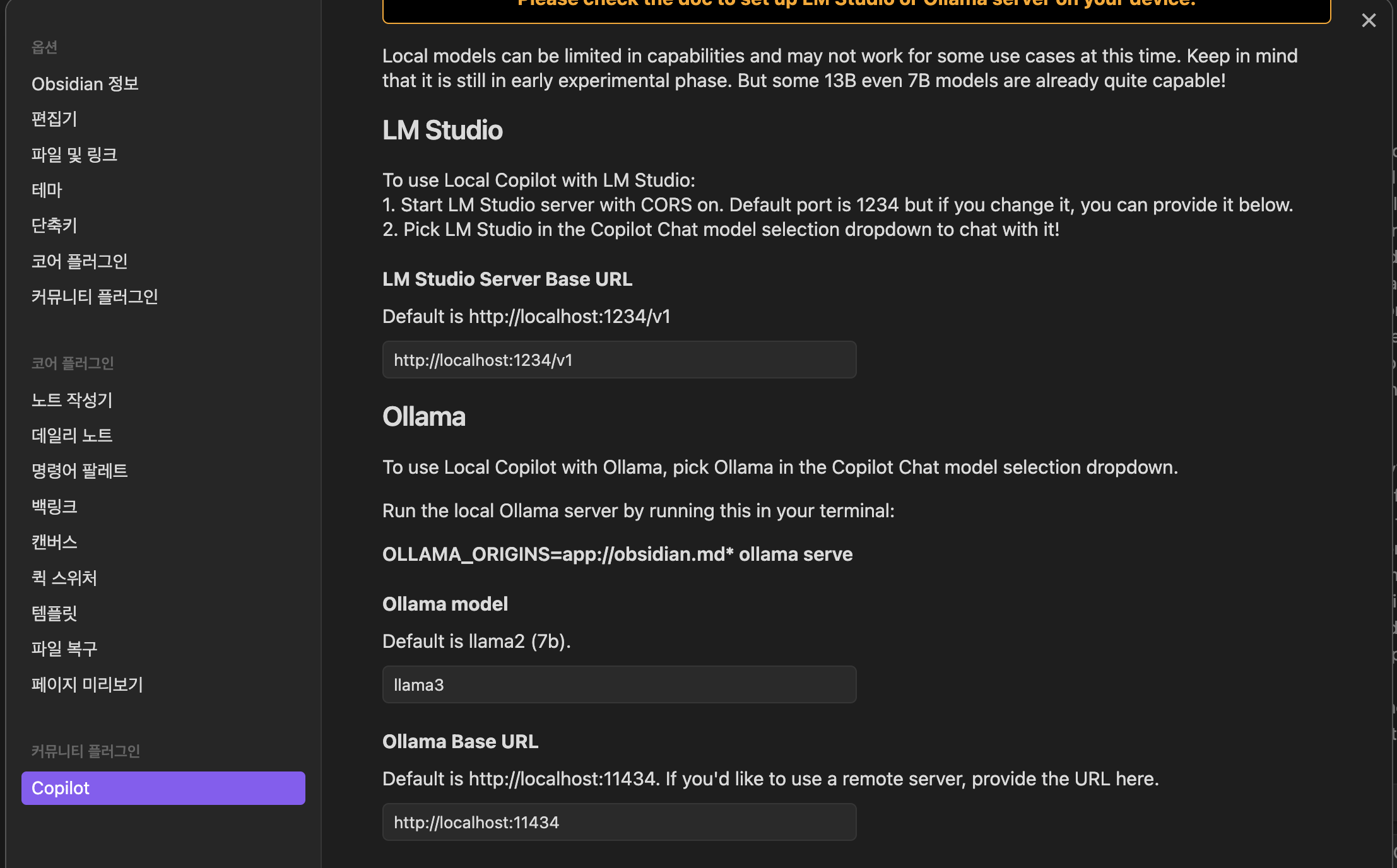
1. 로컬에 Ollama설치 후 server를 띄우면 이렇게 확인 가능함.

2. Python에서 의존성 설치 (venv환경에서 진행)
- 필요에 따른 설치
pip install gtts
pip install ollama
pip install playsound
pip3 install PyObjC
pip install SpeechRecognition
pip install -U pip
pip install -U pyaudio
'장난감 정리 중' 카테고리의 다른 글
| Whisper WebUI 로컬에 설치/실행 하기 (1) | 2024.07.26 |
|---|---|
| Obsidian에서 ollama사용 (with Copilot) (0) | 2024.07.26 |
| Synology NAS 2대를 UPS하나로 묶는 간단한 설정 (0) | 2022.11.23 |
| windows 11에서 한영전환 Shift + Space로 변경하기 (0) | 2022.11.01 |
| Android 적응형 배너 적용 (0) | 2022.08.07 |